Abstract
This paper introduces an enhancement to PQCanvass: natural language document retrieval powered by vector embedding technology. This feature enables engineers to search Power Monitors Inc.’s white paper library using conceptual queries rather than exact keyword matching. By moving the search architecture from traditional keyword indexing to semantic vector space modeling, PMI has eliminated the requirement for precise terminology knowledge that previously limited search effectiveness. Implementation testing demonstrates improvements in document retrieval and workflow efficiency. This paper examines the technology’s underlying mechanism, provides tips for creating an effective query, and previews integration with our forthcoming PQ Assistant diagnostic tool, currently in beta testing with select users.
Using the Feature
To access this feature, you’ll need a PQ Canvass account. If you don’t have one, please contact our support team for assistance. For existing account holders, simply visit pqcanvass.powermonitors.com and sign in.
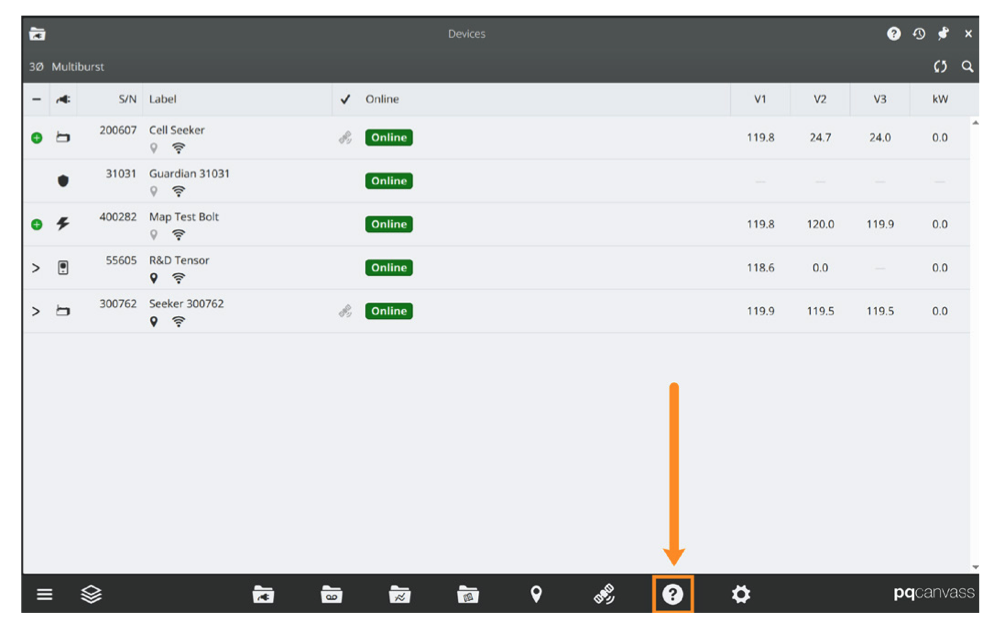
If signing in for the first time, you’ll arrive at the Help Center by default; otherwise, you can locate it by clicking the question mark icon on the toolbar. Once in the Help Center, enter your search query and click “Search.” Three relevant papers will appear, which you can view or download by clicking on them.
How Vector Embeddings Work
The search functionality employs vector embedding technology, a natural language processing technique that transforms semantic content into high-dimensional numerical representations. This implementation processes textual input—ranging from individual terms to complete documents—through a trained neural network architecture that generates a multi-dimensional vector space based on contextual relationships and semantic patterns.
Our system utilizes a state-of-the-art embedding model that generates high-resolution semantic embeddings, optimized for capturing technical terminology and contextual nuances specific to power engineering documentation. The model processes document segments and search queries through identical tokenization and encoding pathways to ensure dimensional consistency.
When processing white papers for indexing, the system segments each document into components and maps these segments to their corresponding vector representations. These representations capture not only keyword presence but also contextual significance, technical relationships, and conceptual proximity between terms.
For search, user queries undergo identical vector transformation. The system then performs similarity analysis between the query vector and document vectors. This approach identifies documents with the highest vector space proximity to the query, regardless of exact terminology matches.
Effective Search Methodology
To better illustrate how vector embedding based search works, it is worth discussing what makes for an effective query. This section outlines evidence-based recommendations for better document retrieval.
First, include relevant technical context rather than isolated terms. A query like “IEEE 519 compliance for industrial VFD installations” yields more precise results than simply “IEEE 519” by providing the system with more application parameters. This specificity narrows the vector space to more relevant document clusters.
Second, construct grammatically complete queries rather than terminology strings. The embedding architecture processes “Protective measures against transformer-induced voltage sags” more effectively than “sag mitigation techniques transformer” because the complete syntax provides clearer semantic markers for vector mapping.
Third, incorporate situational elements including equipment specifications, facility characteristics, and observed phenomena. A query specifying “Voltage fluctuations affecting LED lighting in commercial buildings” enables the system to identify documents addressing similar technical scenarios even when terminology differs. This contextual framing will improve document retrieval precision across all applications.
Finally, consider query refinement as an iterative process. Initial search results provide valuable feedback on terminology alignment with the corpus. When evaluating retrieved documents, identify technical terms or standards that appear frequently, then incorporate these into follow-up queries. This refinement technique is particularly effective when investigating complex power quality phenomena that may be described using multiple technical frameworks.
Case Study
To demonstrate the vector embedding technology’s practical application, consider the following scenario involving a utility field technician investigating residential power quality complaints.
When a technician entered the search query “Residents reporting eye strain around lights” into PQCanvass, the system identified “IEEE Std 141 Flicker Curve vs IEEE 1453 Flicker Meter” as the most relevant document, despite the absence of the terms “strain” or “residents” in the paper. The algorithm recognized the semantic relationship between visual discomfort terminology and the technical flicker measurement standards.
The retrieved document contained this relevant passage: “The point at which flicker becomes irritating or even perceivable varies person to person and can depend on many factors. Some of these factors include a person’s age, neurological, psychological and overall health, and the individual’s critical flicker frequency.”
This example illustrates how the vector embedding system bridges the terminology gap between field observations and technical documentation, enabling faster issue resolution.
PQ Assistant
PMI has developed a PQ Assistant that connects waveform visualization with contextual document retrieval. This system, currently in beta testing with select PQ Canvass users, provides an interface for engineers to submit waveform data and receive relevant technical documentation.
The assistant presents a conversational interface where engineers can discuss observed waveform characteristics and request applicable reference materials. The vector embedding framework then identifies and retrieves the most relevant technical documentation based on the conversation history.
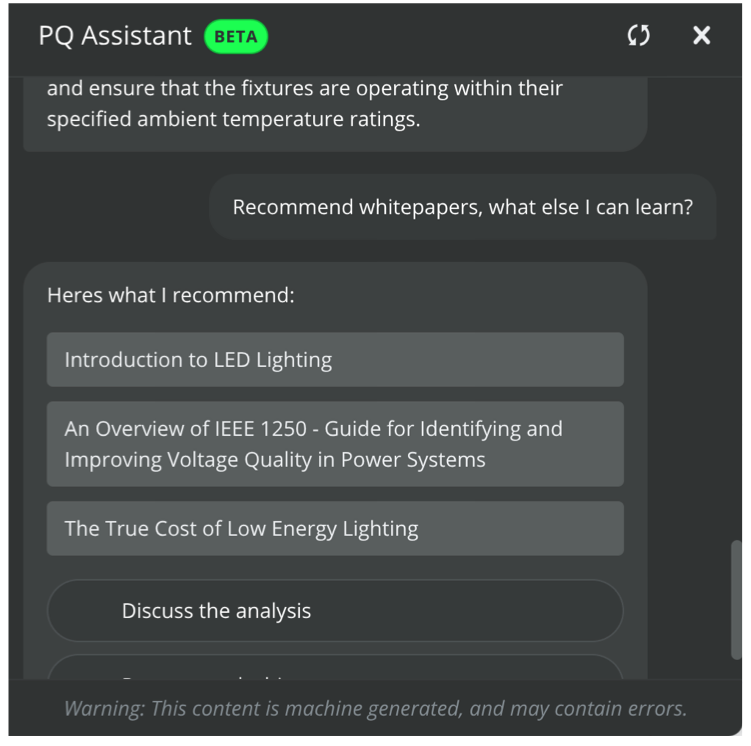
A field implementation case demonstrates the system’s practical application: when investigating residential lighting failures, a technician captured multiple capacitor closing events using a Revolution monitor. After examining the waveform visualization, the technician requested related documentation through the PQ Assistant interface. This workflow eliminated the need for separate documentation searches, saving time and providing more relevant information faster.
Conclusion
This paper has examined the implementation of vector embedding technology for technical document retrieval within PQCanvass. The embedding model implemented in this system offers dimensional precision that effectively captures power engineering terminology relationships and contextual nuances beyond traditional search architectures. By segmenting technical documentation into overlapping components and mapping them to high-dimensional vector representations, the system establishes semantic relationships between observed field phenomena and formal engineering documentation.
The integration of this technology with the PQ Assistant establishes a foundation for improved diagnostic workflows. By connecting waveform visualization with contextual document retrieval, PMI provides power quality engineers with a technical framework that reduces the cognitive barriers between observation and resolution. Future development will focus on expanding the vector embedding model’s training corpus with domain-specific engineering documentation and integrating additional power quality analytical tools into PQCanvass. These advancements will continue to enhance the system’s diagnostic capabilities while maintaining the technical precision required for power quality analysis.
